i-am.ws |
Netpbm without Libraries
Last seven years I've been building a large web application that is doing a lot of image manipulation. When I say large, we're talking here about fifty thousand lines of code. To achieve that the only way is to script and automate all the image processing. Where my web front-end is in Perl, the back-end is 100% based on the Linux netpbm tools (get it here). And if netpbm is missing some functionality that I require, then I will typically develop a new netpbm tool and contribute it to the package (that's how pamwipeout and pamrubber came into being).
After thirty years the netpbm package is now pretty substantial in size. So for creating a tool that is small and rather custom it is often easier if you don't need to do the full netpbm install and build. But you will need your own code to read, analyze and write your PNM files. And of course in those cases I don't submit the results to sourceforge.

As an example, these two images one with blue fan parts (air intake in the datacenter cold aisle) and the other with red ones (fan exhaust in the hot aisle). Often I have only one of the two pictures and I need to convert it. At first I would use Gimp to manually convert from one to the other – or vice versa – but automating it makes the process much faster and less error prone.
The transformation here is a simple process of finding the blue pixels and then changing the hue (hue/saturation/value) to red. The procedure is to convert r/g/b to h/s/v, then shift the hue from blue to red and convert back to r/g/b. A not too complex operation and a nice opportunity to bring out my home grown netpbm code. When it is for only a custom single purpose you can typically simplify things a lot, like only doing 8-bit PPM and skipping PBM, PAM, etc. Plus skipping a lot or error validation. In this case resulting in just 500 lines of code, not too bad.
This program is only meant as an example framework and therefore named ppm2ppm. After extending it with your own functionality, you should of course rename it to something more meaningful like in this case maybe "ppmblue2red". Btw where the official netpbm tools are typically using "to" in their names (like pamtopng), I try not to do that in my home-grown NetPBM programs, using a "2" instead to distinguish things.
Posted at 12:55PM Dec 21, 2018 by WWWillem in Software |
PAM to PNG Converter
Five years ago I wrote on this blog (just scroll down) about a "Quick & Dirty" pam2png utility to add alpha channel handling to pnmtopng. Which is part of the NetPBM graphics toolset in Linux. The pnmtopng software had over a lifetime of twenty years seen so many revisions – by different people with different visions – that it was finally time for a full rewrite.
Over those years the code nearly doubled in size. With pamtopng I brought it back to a quarter of the current pnmtopng. Because today's computers are so much faster than twenty years ago and because memory is now plentiful, all kinds of very clever but complex optimizations to compress the PNG image could be removed. And if you need maximum compression, there is always pngcrush. At the same time 60% of the command-line switches were dropped.
More detailed information about pamtopng can be found on the man-page at SourceForge. Which is also the place to find the source code. Because of the NetPBM software release system, when it comes to Linux distro's pamtopng will not always be included. For example it is part of Fedora since version 23, but as of today you won't find it yet in CentOS.
Posted at 04:01PM Dec 30, 2016 by WWWillem in Software |
Tuning ffmpeg for MythTV
MythTV is my default way of watching television. It stores the content as MPEG2 files, the video with a bitrate of 6000 kb/sec and the audio with 384 kb/sec. For the purpose of watching the content outside of my home, I do post-processing to reduce the filesize such that it can be copied over the Internet. The tool of choice is of course 'ffmpeg' which has a large number of flags to control the output. I used -qmin, -qmax and -qscale to tune down the file size. For audio, the ffmeg help-page says that without flags the output will have the same quality as the input, which sounds good.
I started to dig deeper and discovered that what I was doing was far from optimal. On the video front the compression was so high that it resulted into those "quilt pattern" squares. Which I accepted as a fact of life, but while playing and testing, I found that I could get the same level of compression, but with a much better picture quality, by simply reducing the video bit-rate instead of using the qscale flag.
Then I discovered an even bigger issue with the audio. The default behavior (at least in my case) appears to be not to copy the audio bit-rate from the input file but to use 64 kb/sec, down from 384. And that results in big distortions, especially with music. I started experimenting and 128 kb/sec gives pretty acceptable audio, while the difference between 256 and the original 384 kb/sec can't be noticed with your average TV program.
So, here is how I am compressing now, which reduces the file size to a quarter of the original.
# ffmpeg -y -i file-in.mpg -vcodec msmpeg4 -b 1000k -ab 128k file-out.avi
Then I started to look at reducing the file size of those MPEG2's for archiving purposes. In this case quality decrease is of course not acceptable. I opted for MP4 as the format and got the following as a good compromise.
# ffmpeg -y -i file-in.mpg -vcodec mpeg4 -b 3000k -ab 256k file-out.mp4
I can't see the difference with the original and it shaves off around a third. Please notice that the video codec is 'msmpeg4' for avi files, while 'mpeg4' for mp4 files.
And now I will have to start recoding half a TB of video content :) ... that will keep my CPU busy for a while.
Posted at 03:25PM Sep 21, 2014 by WWWillem in Software |
Mobile Navigation
Going through some folders with software development projects from the past, I came across this one, which is dating back to the spring of 2003. One of those attempts to get rich quick :) with a startup. The idea was to have a small mobile device with GPS that would show you the map of where you were and then allow you to get directions to the closest coffee shop, gas station, hotel, etc. And then of course sell those ads commercially. Hey, this was still (the end of) the dot-com era. Sounds familiar? Yes, four years later Apple introduced the iPhone, so we're definitely talking here about "prior art".

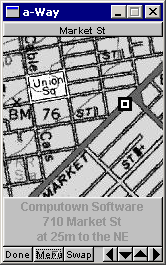

The app got as far as a functioning prototype with data for downtown San Francisco. You see it here searching for hotels, while walking along Market Street. It had maps and aerial photos from the Microsoft TerraServer. Which is an interesting piece of history, because Microsoft got the maps from the USGS, but bought the aerials from the Russians. Not surprising that it only contained photos from space of the USA. :-)
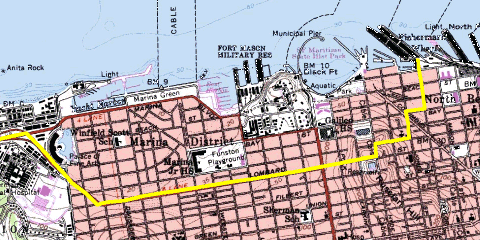
I got my location information about restaurants, shops, theaters, etc from an on-line Yellow Pages database. I also needed a vector based map, because otherwise you can't do proper path planning. Found that in a database from the US Census Bureau called Tiger. The shortest path calculation was of course based on Dijkstra's algorithm.

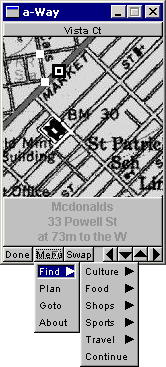
In 2003 the mobile devices of the time were PDAs. Remember those? One startup company called "Agenda" developed a model that was fully based on Linux. Through the serial port and using ppp, you could even telnet and ftp into the device. The GUI couldn't do X-Windows – not enough processing power – but someone created a port of FLTK for it. A nice thing was that you could compile the same code base for desktop Linux, Windows or the Agenda.
The GPS to use was an easy choice, always been a fan of DeLorme units. It connected to the PDA through a serial cable.


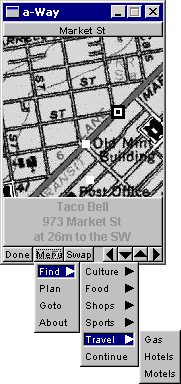
As you can see below, there were various categories to pick from. Or you could do a "Go To" by clicking somewhere on the map. The little white dots are the route to get to your destination. Or you could pick a street name from the Tiger database.
To be honest, by now I have no idea how this could have scaled to cover more than just a city. But it was lots of fun to develop. And it worked.
 |
 |
 |
Posted at 01:20PM Jan 19, 2014 by WWWillem in Software |
Alpha for PNG with NetPBM
As a co-developer of pnmtopng / pngtopnm it's already a long time my plan to update those two NetPBM programs for the PAM format, allowing for proper alpha channel support. On sourceforge you can find a pngtopam program — not sure how full featured it is — but there is currently no pamtopng, which is IMHO the more important of the two.
Two weeks ago I was myself in desperate need for a PAM to PNG converter, and I didn't have the time to do some proper development, therefore decided to do a quick & dirty one. Luckily I wrote 10+ years ago two PngMinus tools, which was targeting the same type of converters, but without the need for the NetPBM libraries.
Long story short, I wrote a "pam2png" utility, which is not as feature rich as a pamtopng program would be, but it does the job. Its main purpose is to convert 4-channel "RGB_ALPHA" pam images to png, but it does the conversion of 2-channel "GRAY_ALPHA" as well. However, the latter wasn't extensively tested.
To be honest, I stopped testing and debugging when the program was good enough for the images I needed to convert to PNG. And I will not spend too much more time on it, because the real goal is a proper pamtopng implementation. But if you find bugs, send me the fixes and I will incorporate them. Don't waste your time on adding functionality, because this is just a temporary job.
Finally, if you don't know how to create those PAM images with R+G+B+A channels, check out the pamstack command. This tool allows you to combine a regular RGB ppm image with an alpha channel image packaged in a pgm file. The README file in the tar-ball shows how to do it.
Posted at 12:33AM Dec 18, 2011 by WWWillem in Software |
jQuery Mobile on Android
I developed an app for BlackBerry PlayBook that is using the jQuery Mobile toolkit to create the user interface. Now jQM is a portable framework that can run on many platforms, ranging from your regular Chrome, FireFox or Safari browser, to mobile devices like iPhone or Android.
Searching for how to deploy jQuery Mobile on Android, most examples are written as a WebApp. The code is loaded on a web-server and you point your Android browser to it to start the app. But what I wanted was everything packaged in an .apk file that can be installed from the Android AppMarket. To achieve this, you have to create a small Java wrapper around your html and JavaScript code. In this tutorial I will be using Eclipse on CentOS as my development platform.
- First step is to create in Eclipse a new project: "File > New > Android Project" and give it a name (let's say "IceCream", I copied the jQM code from a blog by Matt Doyle), select the target and enter the package name, like "ws.iam.icecream". Keep Create Activity checked.
- Next we'll be adding a WebKit WebView to onCreate():
package ws.iam.icecream;
import android.app.Activity;
import android.os.Bundle;
import android.view.Window;
import android.webkit.WebSettings;
import android.webkit.WebView;
import android.webkit.WebViewClient;
public class IceCreamActivity extends Activity {
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
this.requestWindowFeature(Window.FEATURE_NO_TITLE);
setContentView(R.layout.main);
WebView webView = (WebView) findViewById(R.id.webview);
WebSettings webSettings = webView.getSettings();
webSettings.setJavaScriptEnabled(true);
webView.setWebViewClient(new WebViewClient());
webView.loadUrl("file:///android_asset/index.html");
return;
}
}
- And if you want to use HTML5 LocalStorage, you should add after "webSettings.setJavaScriptEnabled()" the following:
webSettings.setDatabaseEnabled(true);
webSettings.setDomStorageEnabled(true);
- This WebView will replace the LinearLayout in res > layout > main.xml.
<WebView xmlns:android="http://schemas.android.com/apk/res/android"
android:id="@+id/webview"
android:layout_width="fill_parent"
android:layout_height="fill_parent"
android:scrollbars="none" />
- While we're at it, we should update the AndroidManifest.xml file. Just after the <use-sdk> parameter, add the following line:
<uses-permission android:name="android.permission.INTERNET"></uses-permission>
- Also we need to prevent Android from creating a new Activity when the user rotates his tablet. Add a parameter to the Activity declaration (for recent SDK versions, this should be android:configChanges="orientation,screenSize"):
<activity
android:name=".IceCreamActivity"
android:label="@string/app_name"
android:configChanges="orientation">
- You probably want to replace the default res > drawable > icon.png files (in three resolutions) with your own.
- Now we get to the core of this tutorial. Which is how to wrap the html, css and javascript of jQuery Mobile. Those files get all placed in the "assets" folder of the Eclipse project. And our Java Activity is attaching to that with the "webView.loadUrl()" call that we saw above. So, right click "assets", then "New > File" and give it the name "index.html". Right click the file and do "Open With > Text Editor" and now copy-paste our Ice Cream Order html code into it.
- Typically the jQuery Mobile javascript libs get loaded from the web. But I prefer to make it part of the package. Again right click "assets" and "New > Folder" and call it "js". Now, outside of Eclipse, copy your "jquery-1.5.2.min.js" and "jquery.mobile-1.0a4.1.min.js" into this "Workspace/IceCream/assets/js" folder. Similarly create a folder "assets/css" and copy "jquery.mobile-1.0a4.1.min.css" into it. (By now you're probably using newer jQM versions, that's ok.)
- At the top of your index.html file, include the following lines:
<link rel="stylesheet" href="css/jquery.mobile-1.0a4.1.min.css" />
<script src="js/jquery-1.5.2.min.js"></script>
<script src="js/jquery.mobile-1.0a4.1.min.js"></script>
and if you have your own javascript and stylesheets, add those as well:
<link rel="stylesheet" href="css/icecream.css" />
<script type="text/javascript" src="js/icecream.js"></script>
Finally, within Eclipse, right click these files and do a "Refresh".
And now you're all set to run your new app. Probably first just in the emulator. Give it a shot and you should see something like this.
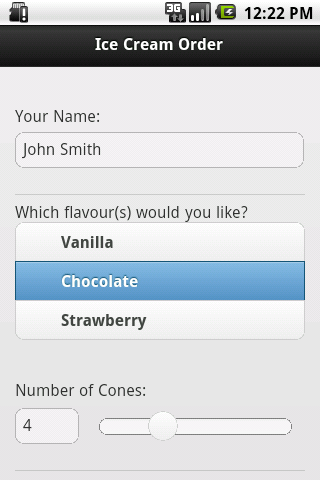
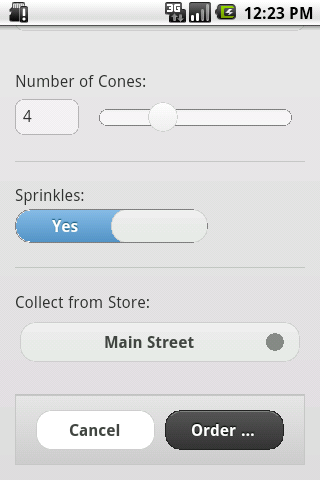
Although this is a working app now, with the java code doing nothing more than being a wrapper, I like to add some native Android functionality. And that is a menu to Reload the app and to Exit it. To do that we've to add two more methods: "onCreateOptionsMenu()" and "onOptionsItemSelected()". Check it out in the complete source code for the Activity.
That all being done, you've to package up the whole thing, sign it and upload it to the Android market. I use Eclipse for this:
- select your IceCream project
- then "File > Export"
- expand the "Android" option and select "Export Android Application", click "Next"
- and "Next" again
- enter the details of your key-store (I assume you have one), click "Next"
- select "Create new key", click "Next"
- give your key the alias name "icecream", enter and confirm a password, give it a validity of 25 years, enter your name and country code and click "Next"
- enter folder and filename "IceCream.apk"
- and finally you can click "Finish".
The resulting packaged and signed application can be uploaded to the Android market, or copied to your Android device using a USB key.
Posted at 01:58PM Nov 20, 2011 by WWWillem in Software |
CentOS 6 boot from USB
Installing CentOS 6 on a laptop without CD/DVD seemed to be easiest by using a Live-USB stick. However, on the net there were warnings that version 6 behaves different from CentOS 5. And indeed, it took me too a couple of attempts before I was successful. I downloaded the LiveCD ISO for CD, not DVD, because with 700 MB, it would fit on the 1 GB USB key I had lying around.
After a little research, I opted for this livecd-iso-to-disk script (or get it from GIT), which promises to do it all automagically. My first problem was that my CentOS 5 system didn't have 'udevadm', which I solved by changing in the script "udevadm info" into "udevinfo" and swapping "udevadm settle" for "udevsettle". After that, the USB key would build, until the stick had to be made bootable. Long story short, the isolinux / extlinux in CentOS 5 is too old. I could have downloaded a more current tarball and built it, but I was too scared that that would break something else.
My solution was to move the whole project to another system running a more current OS, in this case Fedora 15. After installing extlinux with a "yum install syslinux-extlinux", not only my udevadm issues were solved, but it also had a more recent isolinux, version 4. One tip: if you copy everything to the USB key and then at the end something breaks, like my extlinux, you can use the option "--skipcopy" to save quite a bit of time. Finally, I used an ext3 filesystem on my stick and it is a good idea to start each new attempt with a "mkfs.ext3 /dev/sd@#".
After booting from the USB stick, the next steps were of course an "Install to Hard Drive", then a "yum update", followed by using the GUI to install a whole slew of RPM packages.
Posted at 06:03PM Oct 15, 2011 by WWWillem in Software |
PnmBlend Disappearing Act
Recently I was working on an automated tool to create images of 19" racks with their content. I got a nice picture of the new Cisco R42610 rack, but with the doors off, it still showed the hinges. No big deal, but it made the picture a little ugly.
I wanted to let those hinges disappear and had to be able to make it a repeatable thing. Therefore I didn't want to do it with PhotoShop, but preferred to script it using NetPbm. Now, NetPbm didn't have the right tool for the job, so it was time to write my own. Wasn't the first time, ten years ago I wrote together with Alex the pnmtopng/pngtopnm converters and more recently I contributed "pnmmercator", a cartography application.
The result of my current effort is "pnmblend", a little utility that will take the top and bottom row of an image (or the left and right column) and replace everything in between with a fading (or gradient) from one to the other.





On the left you see the rack with the hinges still there. The next picture zooms in and the third shows the piece we've cut out to work on with "pnmblend". After that you see the output of my new utility and the last image is the result of putting it back in the original image using "pnmpaste".
This code isn't yet ready to be included in the official NetPbm package. For that I've to convert it from a 'pnm' to a 'pam' utility. Secondly, the current code isn't based on the NetPbm libraries, but is doing it all in itself. Which could in certain cases even be an advantage.
Update March 2011: This code was included in NetPbm under the name pamwipeout
Posted at 09:14PM Jan 29, 2011 by WWWillem in Software |
Apache mod_substitute
When building my new Apache Roller system, I had quite a few challenges with the i-am.ws domain, served from a web-server in the DMZ and Roller on a Tomcat server in the backend. The mod_proxy Apache module takes care of most of it, but hardcoded URLs in the html code need to be translated as well from the internal IP to the external domain name.
A month went by and I found the solution in stumbling on the "mod_substitute" and "mod_sed" modules. With those, the proxy can fix on the fly the hard-coded URLs generated by Roller. In this scenario, substitute "http://192.168.1.23:8080/roller/" for "http://www.i-am.ws/" and you're all set. The only thing to be aware of is that you must be running a pretty recent version of Apache (2.2.7 for "mod_substitute" and even 2.3 for "mod_sed").
Now that sounds like a done deal, but it took me couple of weekends to figure out a nasty snag with "mod_substitute" and the like. I thought it was caused by mod_proxy and mod_substitute clashing with each other. So I thought I was clever :-) and moved mod_substitute to the back-end. I installed another Apache on a different port (8642) that would do a local proxy to Tomcat (on 8080). It didn't fix the problem, but by doing I discovered that when I retrieved the web-page with "wget" (one of my favorite hacking tools) instead of Firefox, string substitution worked fine. Now my suspision moved to issues with HTTP 1.0 vs. 1.1. Again, that wasn't the case.
Getting desperate, I decided to write my own proxy server. Grabbing some old bits and pieces of code still lying around :-), that wasn't too tough. At first, things went fine and then the same thing happened again. But with my own code – not running in the background – I had a much better handle on debugging. Checking the HTTP headers of the request, I suddenly noticed that Firefox sends to the server an "Accept-Encoding: gzip, deflate" http header record (BTW, same with IE). And yes, the server replied with all html code nicely compressed. Which suddenly explained why all this time mod-substitute couldn't do anything with it. It also explained why wget, not sending that header, was working fine.
For now, I'm sticking with my home-grown proxy, but the proper solution is I guess to use mod_rewrite to get rid of those compression HTTP headers. And then mod_substitute can do what it's supposed to do.
Posted at 11:33AM Apr 25, 2010 by WWWillem in Software |
Yum Local Install
Yesterday I was trying to configure a music player on an old laptop running Fedora 8. It required some additional packages for mp3, but when I tried to do a "yum install gstreamer-plugins-ugly" it appeared that this old stuff didn't exist anymore in any of the on-line repositories.
Luckily, pbone.net came to the rescue. I downloaded the RPM package, then tried to install, but there were a whole slew of dependencies that needed to be resolved first. Damn .... normally it means that one-by-one you've to search the net to figure out which RPM includes that specific shared library and then the result is often even more unresolved dependencies.
Don't know why, but I checked the man-page for yum and found that there is a "localinstall" command. What it does is that you use yum to install an already downloaded rpm package, but it will then use the on-line repositories to resolve the dependencies. Kind of "best of both worlds" approach.
# yum localinstall gstreamer-plugins-ugly-0.10.8-1.fc8.i386.rpm
Of course you have to hope that not too many of the other packages you need has the same issue of having disappeared from the repositories. But luck was on my side yesterday. Couple of minutes later I had my Muine Music Player running and the MP3 music was flowing out of the speakers.
Posted at 11:04AM Mar 21, 2010 by WWWillem in Software |
I-am.WS
All blog entries below this one were written as part of my "blogs.sun.com" weblog. But that blog comes to an end, because around Xmas 2009 I left Oracle/Sun to join Cisco. Similar role, Datacenter Architect for Cisco's new UCS platform, later more about that. As a consequence, I can't add to my old blog anymore and I presume that anyway blogs.sun.com will soon be rolled into one of Oracles blogging sites.
For me, time to figure out another venue. I decided to install my own apache-roller (the same blogging software Sun was using), on a box in my basement running Apache and Tomcat. One of the reasons for going this route was that, couple of years ago, I managed to acquire the domain name "i-am.ws". "WS" being my initials, that seemed pretty appropriate as the new name for a blogging site. The sat image in the header is West Samoa, where these domains originate from.
This not being a "what did we have for dinner" blog, but rather more "food for techies", I have to share here a few of my experiences moving my blog from Sun's IT into my basement. The laptop I'm using, is a "goldie-oldie" PII with 256 MB of RAM. That dates it pretty well and therefore it is running RedHat EL3, nothing fancier, but hey, it's doing the job. Therefore it also has an older MySQL version (3.23.58), the same for glibc, etc.
At first I tried to install latest-greatest Roller 4, which became a disaster, all kinds of dependency conflicts. And that makes sense, on top of a 5 year OS you better build a five year old software stack. However, it can be a little scramble to find all the older sw packages. In this case I "dropped down" to Roller 3.1, picked Java 1.5 SE JDK and Tomcat 5.5. Which combination seems to work pretty well together.
The bigger challenge was that my i-am.ws domain points to another webserver on my LAN, which functions as a proxy to my CMS-Made-Simple, my Myth-Web box and now this Roller instance on Tomcat. Typically I fix the fact that different domains are being served by the same webserver, by creating an Apache HTTPD "Virtual Host" with the following parameters.
ServerName ecliptic.net ServerAlias www.ecliptic.net ServerAdmin webmaster@ecliptic.net DocumentRoot /var/www/html/ecliptic.net
But in this situation, that's not enough. We've to proxy to the tomcat server on the other box. Therefore we need to add a couple of 'ProxyPass' and 'ProxyPassReverse' parameters. The following isn't perfect, but I wanted to have "/" (the root of my domain) point to "/roller/wwwillem" on the Tomcat engine. Which makes things a little trickier.
ServerName i-am.ws ServerAlias www.i-am.ws ServerAdmin webmaster@i-am.ws ProxyPass /roller/roller-ui/ http://192.168.1.23:8080/roller/roller-ui/ ProxyPassReverse /roller/roller-ui/ http://192.168.1.23:8080/roller/roller-ui/ ProxyPass /roller/theme/ http://192.168.1.23:8080/roller/theme/ ProxyPassReverse /roller/theme/ http://192.168.1.23:8080/roller/theme/ ProxyPass / http://192.168.1.23:8080/ ProxyPassReverse / http://192.168.1.23:8080/ ProxyPass /wwwillem/ http://192.168.1.23:80/ ProxyPassReverse /wwwillem/ http://192.168.1.23:80/ ProxyPass / http://192.168.32.54:8080/ ProxyPassReverse / http://192.168.1.23:8080/ CustomLog /var/log/httpd/i-am-ws_access.log common ErrorLog /var/log/httpd/i-am-ws_error.log
Finally, the biggest problem is that Roller generates in many spots HTML with the base URL hard baked into the code. So, if the browser finds the Tomcat application with "i-am.ws" or even "i-am.ws/roller/wwwillem" the html page will be created with hard-coded links to http://http://192.168.1.23:8080/. These should have been relative links of course and probably Roller 4.0 fixed a lot of that, but after googling this for a long time, it seems that there are still many issues around this. I searched for an Apache module that would scrape the html returned to make the necessary corrections, but such a thing doesn't seem to exist.
Anyway, for me the most important thing is to have my WebLog up and running again. In some future I will probably upgrade the whole thing to some newer platform (likely CentOS 6 when that's out, or Fedora 12), but for now, this is good enough. As usual, it was a good learning experience.
Posted at 11:41PM Mar 15, 2010 by WWWillem in Software |
Solaris Security
It's already dark when I leave the hotel, dragging my carry-on behind me. I can turn left, to the pub where the rest of the troops is probably already behind their second beer, but I decide to make a little detour to the right. I walk to the front of the 18-wheeler to see if Dan, the driver of our Project Blackbox rig, is still around. I find him, with big gloves on, between the power generator and the water chiller. He is working hard to make the Blackbox transport ready again. We shake hands to say goodbye.
I met Dan for the first time in Calgary a month or so ago, great guy, not only the driver of our Blackbox demo roadshow unit, but also the one who took the most fabulous pictures of the box in between the high-rise of Calgary's downtown core. Today we are in Vancouver. Different bussiness drivers, but the same crowd that gets inspired by Project Blackbox and sees how it can open new avenues for datacenter expension, consolidation and "going green".

After my goodbye to Dan, who's now off to Mexico City, I join my colleagues for beer and then it's off to the airport. For those of you who are "frequent flying" as well, you know the drill. Empty your pockets, get all your keys and stuff into the grey plastic bin, your laptop in the second bin, your coat in the third, etc.
But now it comes....
One of the security folks, I would guess around 60 years old, sees my Sun badge in the bin next to my coins, my keys and phone. He asks me out of the blue, "but is Solaris free" .... and it is clear he means it in the "free as in beer" sense. It catches me a little off guard, but my reply is "you can just download it, no problem". His counter "yeah, but do I get source code and am I then able to change it?" I try to assure him with "of course, that is what open source is all about". Next question: "but do I need assembler code to do this?" (now you understand why he was at least 50+ :-). I hope I was correct with my answer: "no problem, it's all C code, you will be fine".
And this all happened within 20 seconds, five times the speed of an elevator pitch, while at the same time I was emptying my backpack to get my laptop into the gray plastic bin, etc. Time was flying way too fast!! I would have loved to talk with this guy about what project he was working on. He was a really interesting person. As a day job checking our bags for stupid things like bottles of shampoo, but in the end really interested in how he could modify and improve Solaris.
That's special !!
Posted at 12:20AM Nov 21, 2007 by WWWillem in Software |
Wireless Activate on Boot
Last night I finally found the time to upgrade my laptop from a "too much patched" Solaris 10 5/03 to a latest-greatest "Solaris eXpress Developer Edition". Before we dig into wireless, I've to do a little plug for SXDE. I think it's a great idea. Many users want on their desktop or laptop something that is up-to-date, must have a decent stability, but doesn't have to be as rock-solid as a normal Solaris release. Problem with using standard S10 on a laptop is that drivers can be "way behind". Which is then normally already fixed in Nevada, but running that on the system that my email is depending on is not my piece of cake. Nevada is great, but please on my second system.
SXDE is the sweet spot in-between: Once every 3 months a snapshot is taken of the Nevada code (the bi-weekly release of that is now also called Solaris eXpress, Community Edition, SXCE), which gets then a couple of "fixes only, no new features" debug cycles, is then bundled with Studio 11 and released to us, the Solaris end-users and developer crowd. I think this is great, it's more stable than S11 Nevada, which is really beta code, and still you get all the latest bug-fixes and drivers.
So, I moved over, and everything went very, very smooth. I also rebooted a couple of times, started to customize the system, configured NTP, noticed that SXDE knows about my Artheros WiFi chipset, configured that, and all was great. One of the biggest features for me was that it decided NOT to overwrite my MBR. So, even while my system is running RH and XP in parallel to Solaris, I didn't have to do any of that 'grub' stuff to reinstall the Master Boot Record. Cool.....
For whatever reason, I did a reboot and my system hang with an absolutely black screen. I rebooted in FailSafe mode, but couldn't see anything wrong. So I reinstalled from scratch. And again the first half hour all was OK, but then it would hang like hell. I couldn't even ping the box. I guess that in total I reinstalled 4 times over the weekend, got quite a routine for it :-), but finally I figured out what went wrong.
As usual it was a combination of a mistake by me, and a system that's not foolproof enough. In this case, my mistake was that when I configured Wireless I told it to "Activate on Boot". Made sense. But I don't have an access point, and was simply testing on what my neighbours provided on the 2.4 GHz band. :-) What is the problem, is that if you click "Activate on Boot" and then, when booting, you don't have a proper access point, the system is not properly timing out. At least that is my theory. It simply waits and waits and waits. With the result that the system simply hangs and you have to reinstall from DVD.
I guess that alternatively you can figure out how to reverse that "Active on Boot", while in FailSafe mode. I kept life more simple and from then on didn't touch that checkbox anymore. Which, so far, works pretty fine.
Posted at 11:01PM Mar 25, 2007 by WWWillem in Software |
Solaris 10 Printer Setup
Last time that I had to setup a printer in Solaris, it was an experience straight out of hell. It was 2-3 years ago, on a system running Solaris 9, and I finally got it working, using the Common Unix Printing System (CUPS), but my experience was bad enough that since then I avoided, as well as I could, to get ever involved with printer setup again.
But setting up a Solaris 10 based system recently, to be used as a home PC, I faced the topic again. I read some man-pages and did some Googling. After some erroneous first attempts, I checked out docs.sun.com and was pointed to "printmgr". Which has improved hugely since two years ago.
The printer I had to setup was a cheap HP Deskjet 812C. And to my surprise, the list of printers preconfigured in printmgr is biiiiggg, also including my little Deskjet. Because this is a parallel port connected printer, the device it resides at is "/dev/printers/0". So far so good! See here is what I had to do to seup.
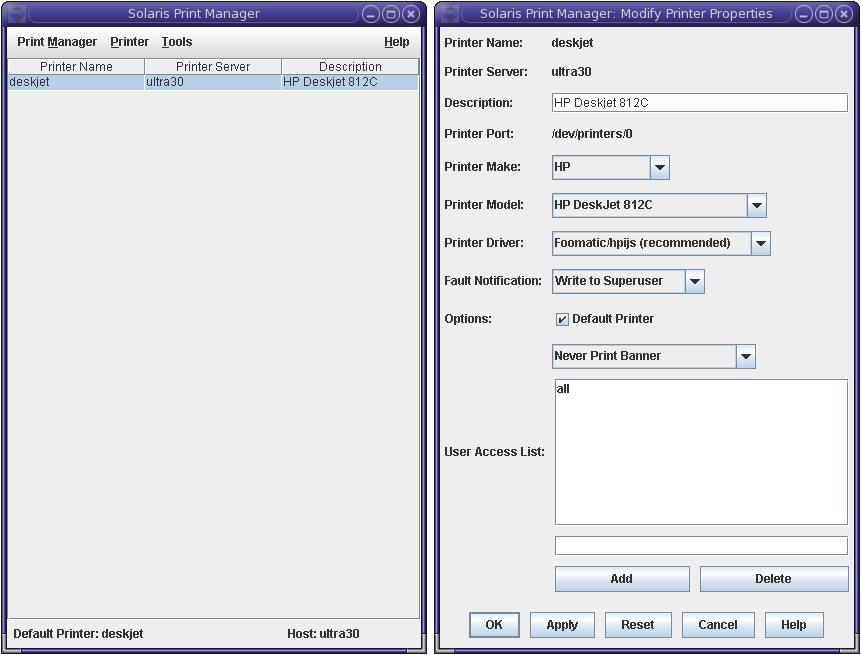
click for full-size
After this I tested with "lp -d deskjet /etc/nodename" and the textual printout was fine. Then it was time to start Mozilla and print a page with graphics and color. Also this worked out-of-the-box.
The last thing to do was to configure the printer in StarOffice. Because StarOffice runs on Windows, Linux, Solaris, OS-X and a couple of other systems, it doesn't make use of the underlying printer subsystem, but has its own. Which is a hassle, but from a software development point of view, I understand why they did it like that. To configure the new printer in StarOffice 8, go to Launch -> Applications -> Office -> Printer Administration. And then I ran out of luck. StarOffice knows only about one HP Deskjet printer and that was of course not the model I had. I still configured using that driver, and I got printouts, but there were white bands every inch and couple of other formatting issues. So, that was not the way to go.
Time to pull out of my bag of tricks a goldie-oldie, I've used for years with success. When setting up a PC, I always configure a HP LaserJet III and an Apple LaserWriter II printer. The first driver can be used for any printer that uses PCL, while the latter is the lowest common denominator for PostScript based printers. OK, you won't get the use of features like two-sided printing or using other paper bins, but for basic printing these two configs are good enough.
Back to StarOffice, I selected the driver for the "HP LasterJet III PostScript Plus" and printed a test page. All was fine, including color. Which was a bonus, knowing that the LJ III was a B&W laser printer.
Posted at 01:48PM Dec 30, 2006 by WWWillem in Software |
Solaris Install + USB
Last night ... mmm, more early this morning :-) ... I was installing OpenSolaris SDX beta (Nevada build #55) and forgot that my USB external drive was still plugged in. This happened because I had downloaded on that drive the 4 Gig ISO image and then burnt it to a DVD.
The install went well, with the only muddy thing that my bootdisk had become c2d0 and not c0d0, what I'm used to. But still: so far, so good. After login I noticed the USB partition being auto-mounted, which is good, and I suddenly understood what had happened. The USB device has one way or another a higher priority over the ATA harddisk and therefore the bootdisk becomes c2d0. Which is of course not what you want to happen.
You can imagine that when I unmounted the USB disk and rebooted, the system needed some deep hard thinking – read "long timeouts" – before it understood where to find its MBR. In short: don't do this!! I took the easy way out and reinstalled everything from scratch, which was not too bad but could have been avoided. Lesson to learn: unplug every USB stick or device before you install an OS.
Posted at 08:25PM Dec 28, 2006 by WWWillem in Software |